Linking
本文最后更新于:October 30, 2022 pm
This blog derives from my notes while reading Chapter7 Linking from Computer Systems: A Programmers Perspective
Course Website: CS:APP3e, Bryant and O’Hallaron (cmu.edu)
Book: Computer Systems: A Programmer’s Perspective: 9780134092669: Computer Science Books @ Amazon.com
This post is under elaboration
Introduction
Generally, the process of linking can take place at any of the following 3:
compile time:when src tranlated to machine code
load time: when program is loaded into memory and executed by loader
run time: by some application programs
Significance: without linking, a large program will corresponds to one certain source file.
Compiler Drivers
gcc, cc .. are called compiler driver, which then invokes language preprocessor, compiler, assembler, linkers when in need.
compiling process:

process:
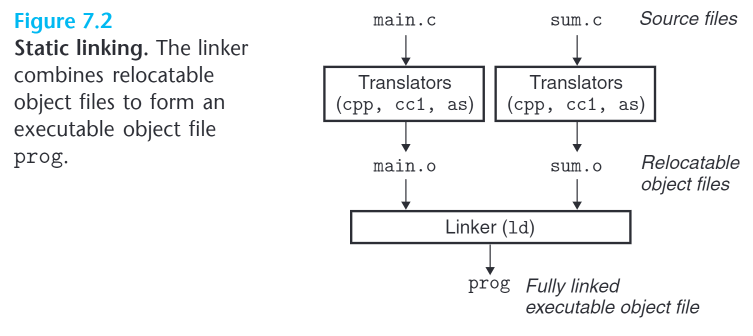
cpp: c preprocessor, translates source file into intermediate file
cpp [other args] main.c /tmp/main.i
cc1: C compiler(cc1), translates main.i into assembly-language file main.s
cc1 /tmp/main.i -Og [other arguments] -o /tmp/main.s
This program is internal to gcc, and not available from shell, the actual part that does compilation.
as: assembler, translates main.s into binary ==relocatable object file==
After the same process for sum.c:
ld: combines main.o and sum.o, along with necessary system object files, to create ==binary executable object file==.
ld -o prog [system object and args] /tmp/main.o /tmp/sum.o
./prog
shell invokes a function in os called loader, which copies codes and data in the bin into memory, and hand over its control to the beginning of the program.
Static Linking
Static linkers takes command line args and a collection of relocatable object files and output a fully linked executable object file, ready for load and run.
relocatable object files: contains various code and data sections, each is a contiguous sequence of bytes:
- one for instructions
- one for initialized global vars
- uninitialized vars
- …(?)
==Keep in mind that these files are merely blocks of bytes==.
To build the executable, the linker must perform 2 tasks:
symbol resolution
Obj files define and reference ==symbols==, it might corresponds to a function, global var, static var.
The purpose of this procedure is to ==associate each symbol with exactly one definition==.
relocation
The starting address of each obj file is 0x0, thus the linker needs to relocate these sections with each symbol definition, and then modify all its reference to its exact memory location.
This procedure is executed blindly following instructions generated by assemblers, called ==relocation entries==.
Object Files
category:
relocatable object file: contains bin codes and data in a form that can be combined with other relocatable obj files at compile time to create executable obj files.
executable obj file: ready to be loaded and executed.
shared object file: a special type of relocatable obj file that can be ==loaded into memory and linked dynamically, at either load time or run time==.
Object files are organized in some specific format, which may vary.
| Platform | Format |
|---|---|
| Windows | Portable Executable |
| Mac OS-X | Mach-O |
| x86-64 Linux/Unix | Executable and Linkable Format(ELF) |
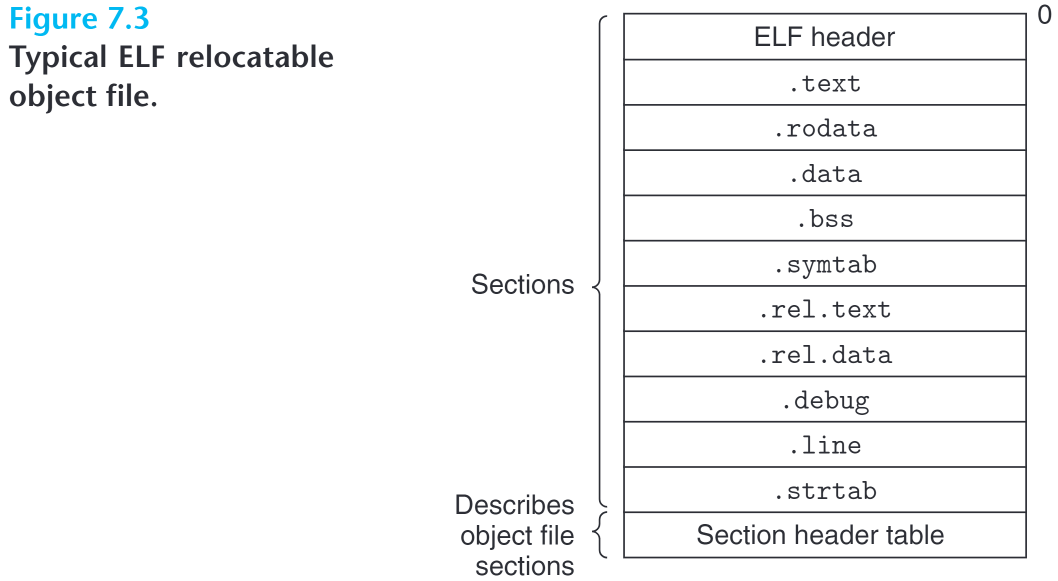
Relocatable Object Files
Elf Format
| Section | Description | Comment |
|---|---|---|
| ELF Header | 16-byte, word size & byte ordering | Begins at address 0 Also a section |
| Size of the ELF Header | ||
| Object file type (relocatable, executable, shared) | ||
| machine type (x86_64) | ||
| file offset of section header table && size, number of various sections | ||
| Section header table | locations & sizes of various sections | each entry is fixed-size and represents a section in the file |
| .text | machine code of exe | |
| .rodata | read-only data( string literal, switch jump table) | |
| .data | Initialized global/static C variable | |
| .bss | Uninitialized global/static C variable, as well as any such variables initialized to 0 | This section is just a placeholder and occupies no actual space in the obj file In other words, the object file doesn’t need to remember value 0 |
| .symtab | symbol table recording functions && global variables defined / referenced in the program |
Unlike the .symtab in compiler, here it won’t record any local variables |
| .rel.text | List of locations in .text section that need modification when linking with other object files. | featuring external functions && global variables This section is omitted in executable object file unless explicit command |
| .rel.data | Relocation information for any global variables referenced/ defined by this module | Generally, this means any global variable initialized with the address of some global variable, or externally defined global variable |
| .debug | debugging symbol table with entries for: local variables typedef-s global variables defined/referenced original C source file |
only present when compiled with flag -g |
| .line | A mapping between line numbers in C source file and .text instructions | only present when compiled with flag -g |
| .strtab | string table for symbol tables in .symtab && .debug sections section names in section headers |
a sequence of null-terminated character strings |
Symbols and Symbol tables
In the context of a linker, the symbols in each relocatable object module can be categorized into :
global symbols:
define by this module, can be referenced by other modules
e.g: nonstatic C functions & global variables
referenced by this module, but defined by some other module
corresponds to the type above in other modules
local symbols
defined & referenced exclusively by this module, static C functions && static global variables
These symbols are visible anywhere in module m, but transparent in other modules
Reclaim: local automatic variables are of no interest to linkers.
.symtab Entry Struct
symbol tables are built by assemblers, using symbols in xxx.s assembly-language file exported by the compiler.
An ELF symbol is contained in .symtab section, containing an array of entries, with each entry denoting a symbol
1 | |
Elf64_Symbol::name
For relocatable object files, the Elf64_Symbol::value is the offset to the beginning of the .symtab
Elf64_Symbol::value
Address of the symbol. For relocatable modules, its an offset from the beginning of the section where the object is defined. For executable object files, it’s an absolute run time address.
Elf64_Symbol::size
Size of the object in bytes.
For functions, it means how many instructions does this subroutine involve. For objects, it means the memory occupied.
Elf64_Symbol::type
Either data or function
Elf64_Symbol::binding
Indicate whether the symbol is local or not
In some type of object files, it can also contain an entry for each section, and even assimilate the full path of the original source file.
Elf64_Symbol::section && Elf64_Symbol::value
Navigate the symbol to the entry of the symbol table.
==3 special pseudo-sections==:
- ABS : symbols that shouldn’t be relocated
- UNDEF: symbols referenced by not defined in this module
- COMMON: uninitialized data objects not yet allocated.
- For this case:
- value field gives alignment requirements
- size field gives minimum size
- For this case:
These pseudo-sections only exist in relocatable object files.
Modern version of gcc distinct COMMON and .bss :
- COMMON: uninitialized global vairables
- .bss: uninitialized static vars, global/static vars initialized to 0
GCC does this for sake of symbol resolution.
use ==readelf== to check elf information.
Example:
The last 3 entries of .symtab in main.o:

Ndx here means which section the symbol lies in, with 1 denoting .text, and 3 denoting .data.
Symbol Resolution
The symbol table associate each symbol reference with exactly one symbol definition.
Local and Global Symbol Resolution
For local symbols in some module, symbol resolution is straightforward, each local symbol is only allowed one definition, and each static local variable is guaranteed with a unique link name.
For references to global symbols:
When compiler encounters a symbol which is not defined but declared( i.e a var/func) in current module, it generates a linker symbol table entry for that, and then leaves it for linker. If the linker again can’t find the definition of the symbol, there will be a linking error( often cryptic).
1 | |
The compiler will run smoothly, while the linker will signal error:

There are times when multiple object modules defines global symbols with the same name, in which case the linker need either flagging an error or favoring one of those definitions and discarding the rest.
Specifically on Linux, it is cooperated by the compiler, assembler, linker, and thus sometimes introduce baffling bugs.
For C++
In C++, programmer can create overload methods.
The compiler encode each unique function with its parameter list and name in combination into a unique name for linking.
The encoding process is called mangling, and the inverse process is demangling.
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16namespace wikipedia
{
class article
{
public:
std::string format (); // = _ZN9wikipedia7article6formatEv
bool print_to (std::ostream&); // = _ZN9wikipedia7article8print_toERSo
class wikilink
{
public:
wikilink (std::string const& name); // = _ZN9wikipedia7article8wikilinkC1ERKSs
};
};
}All mangled symbols begin with
_Z(note that an identifier beginning with an underscore followed by a capital letter is a reserved identifier in C, so conflict with user identifiers is avoided); for nested names (including both namespaces and classes), this is followed byN, then a series of <length, id> pairs (the length being the length of the next identifier), and finallyE. For example,wikipedia::article::formatbecomes:_ZN9wikipedia7article6formatEFor functions, this is then followed by the type information; as
format()is avoidfunction, this is simplyv; hence:_ZN9wikipedia7article6formatEv
Resolve Duplicate Symbol Names
Here we describe how Linux system resolves global symbols defined in different modules but with the same name.
At compile time, the compiler exports each global symbol as strong/weak, and then the assembler encodes this information implicitly in .symtab
Strong Symbols: functions && initialized global vars
Weak Symbols: Uninitialized global vars
Rule of resolving identical symbols:
- Each strong symbol must distinguish in name
- When a name is assigned to a strong symbol and multiple weak symbols, choose the strong symbol
- When a name is assigned to any number of weak symbols only, choose any one of them.
Note that the linker usually signals nothing when some symbol name is defined multiple times.
Note also that a function and a global variable also can’t share a name.
When applying rule 2 and 3, and duplicate symbol definition has different types, insidious run time bugs might transpire.
1 | |
On x86-64/Linux machine, doubles are 8 byte. and ints are 4 bytes. When assigning value to the “double” x, the “int” x only gets the second half of the ieee floating point representation in 2’s complement

To debug this, use gcc flag -fno-common or -Werror to let the linker issue errors instead of just warnings.
Linking with static libraries
In practice, when compiling programs the linker might invoke static libraries. Usually the distributor use a mechanism provided by the compilation system and package all related object modules into a single file, aka static library. It is regarded as an input file to the linker, and when building an executable file, the linker copies only the object modules that are referenced into the app program.
Consider how to provide standard library functions without static libraries:
Let compiler recognize calls to standard functions and then generate function definitions
Pascal too this strategy, but it’s not feasible for C because of the massive number of standard functions.
This will exponentially increase compiler design complexity, as well as each modification to some standard library function will spawn a new version of compiler.
But to application programmers, it’s convenient for all standard functions are always available.
Put all standard C functions in a single relocatable object module, say libc.o
Once programmers all remember to link libc.o, this mechanism is somehow still convenient for app programmers, and it also decouples compilers from libraries.
Except that from now on, every executable file will contain a complete copy of libc.o, which is not disk space friendly.
What’s worse is that each running program will contain such copy in main memory, yak.
Any slight modification to the library source file will also lead to recompilation of the whole library into libc.o

Separate libc.o into printf.o, scanf.o ,…
All good, but when linking executable programs the programmer will be rather miserable.
Ultimate solution
Compile standard functions into separate object modules and package them into a single static library file.
When need linking such files, simply specify the library name
At link time, the linker only copy the object module that are referenced (usually function_name.o ).Actually in practice, C compiler drivers always pass libc.a to the linker.
On Linux system, static libraries are stored on disk with the format called archive. An archive is a collection of relocatable object files, with a header that describes the size and location of each member object file. These files have suffix .a
A Juicy Example
1 | |
To compile and create an archive:
To use this library:
1 | |
or equally, use explicitly linking
The anatomy of building procedure:
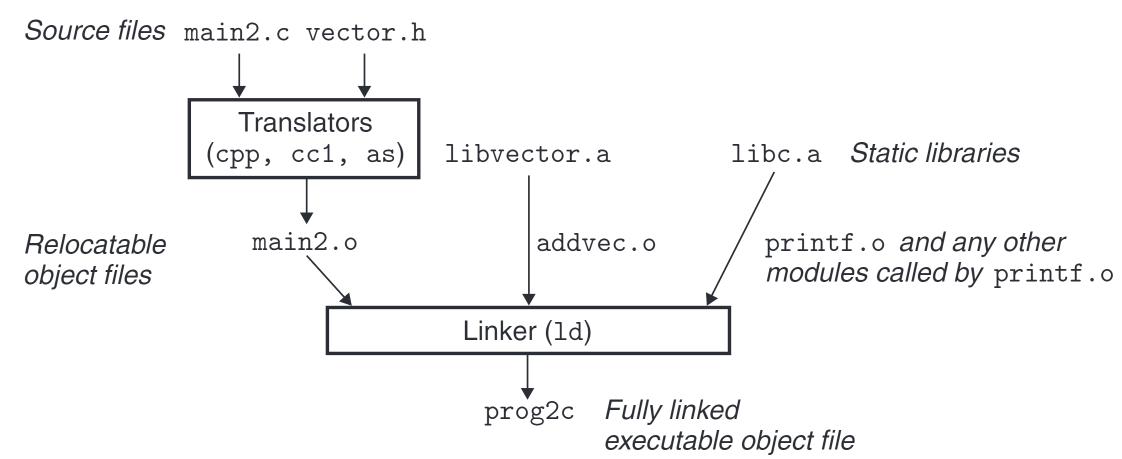
Note here the flag -static tells the linker to build fully linked executable file that needs no further linking at load time. and can be loaded into memory and run directly.
Also note that multvec.o is not referenced so that it’s not copied into the executable file either.
How Linkers Use Static Libraries to Resolve References
Linking libraries can sometimes cause confusing problems because many programmers don’t know how Linux linker resolve external references.
During symbol resolution phase, the linker scans the relocatable object files and archives left to right in the same sequential order that they appear on the compiler driver’s command line. (Any .c files are also translated into .o files).
During scanning, 3 sets are maintained:
- $E$ : a set of relocatable files need merging into the executable file
- $U$ : unresolved symbols(i.e., symbols referenced but not defined)
- $D$ : symbols that have been defined in previous input files
Resolving Algorithm:

With resolving algorithm described as above, it transpired that the order that we input object files and library files are significant. If a library that could have provided some symbols happen to appear before your object file, the library will simply be discarded and linking will fail.

Generally, libraries should all come after your object files in command line. Sometimes, there are dependencies between libraries, so that the programmers shall topologically sort those dependencies. It’s acceptable to input some library multiple times to resolve symbols.
Suppose foo.c calls a function in libx.a, which calls a function in liby.a, which again calls a function in libx.a, to link the executable file, we need
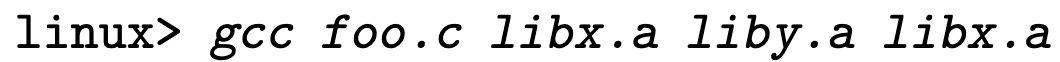
We can also alternatiely combine libx.a and liby.a into one archive file.
Relocation
After all symbols have been resolved, the linker has finished associating each symbol reference in the code with exactly one symbol definition——to be more specifically, one symtol table entry in one of its input object modules. The linker knows
For variables, the linker knows whether it has been initialized, and its size. For functions, the linker also konw its start address, as well as the size of the binary instruction in the object module it belongs to.
Now comes the relocation step, where the linker does the following 2 things:
Relocating sections and symbol definitions
All sections scattered in different object modules of the same type are to be merged into one cohesive section and thus become a single section in the executable object file. .data are merged into one.
The linker will assigns run-time memory address to these new aggregate sections, to each section defined by input modules, and to each symbol defined by input modules.
Upon finish, each instruction and each global variable will have its unique run-time address in the output executable object file.
Relocating symbol references within sections
The linker modifies evrey symbol reference in the body of the code an data sections, by relying on the relocation entries, a kind of data structures in relocatable object modules.
Relocation Entries
When the assembler is generating an object module, it hardly knows the address the the code and data of its output in the scale of the whole executable file after the output is linked with some other files, no to mention the locations of any externally defined functions or global variables refernenced by this module.
That’s why some work shall be left to the linker. So how is this solved?
Whenever the assembler encounters a refernece to an object whose ultimate location is unknown, it creates a relocaion entry for that reference. The linker can thus follow these information and replace those reference with real addresses.
Relocation entries for code are stored in .rel.text, and similarly .rel.data for data.
1 | |
| Field | Description | Comment |
|---|---|---|
| offset | Section offset, need modification | For each reference occurence count, an entry is generated. |
| type | How to modify the new reference | |
| symbol | symbol table index | |
| addend | Signed constant | For some type of modification, it works as a bias. |
Standard ELF defines 32 different relocation types, here we only discuss 2 most basic relocation types:
R_X86_64_PC32
Relocate a reference that uses a 32-bit PC-relative address. Here PC denote the program counter. The address of the next address is the offset encoded in the current instruction plus the current value of PC.
R_X86_64_32
Relocate a reference that uses a 32-bit absolute address. When executing, the address the the next instruction is encoded in the current instruction itself.
Note: These 2 relocation types only support x86_64 small code model, which assumes the total size of the code and data in the executable object file is smaller than 2GB, which is the ultimate scale 32-bit signed addressing can handle. GCC use this model in default, programmers can compile with flag -mcmodel=medium / -mcmodel=large.
Relocating Symbol References
Recall how the linker does symbol resolution. During symbol resolution, the linker maintains 3 sets, say $U,\ E, and\ D$. When resolving a symbol from undefined state——the section field in the symbol’s entry in .symtab is marked as UDF, the linker remove a symbol from $U$ and add it to $D$. Later, the linker relocates sections and symbol definitions.
Thus keep in mind from now on: all symbols, new aggregate sections and scattering sections in all separate object modules have their own unique run-time address.
The following pseudocode describes the relocation algorithm:
1 | |
Take the program for example, we will describe how the linker performs relocation.
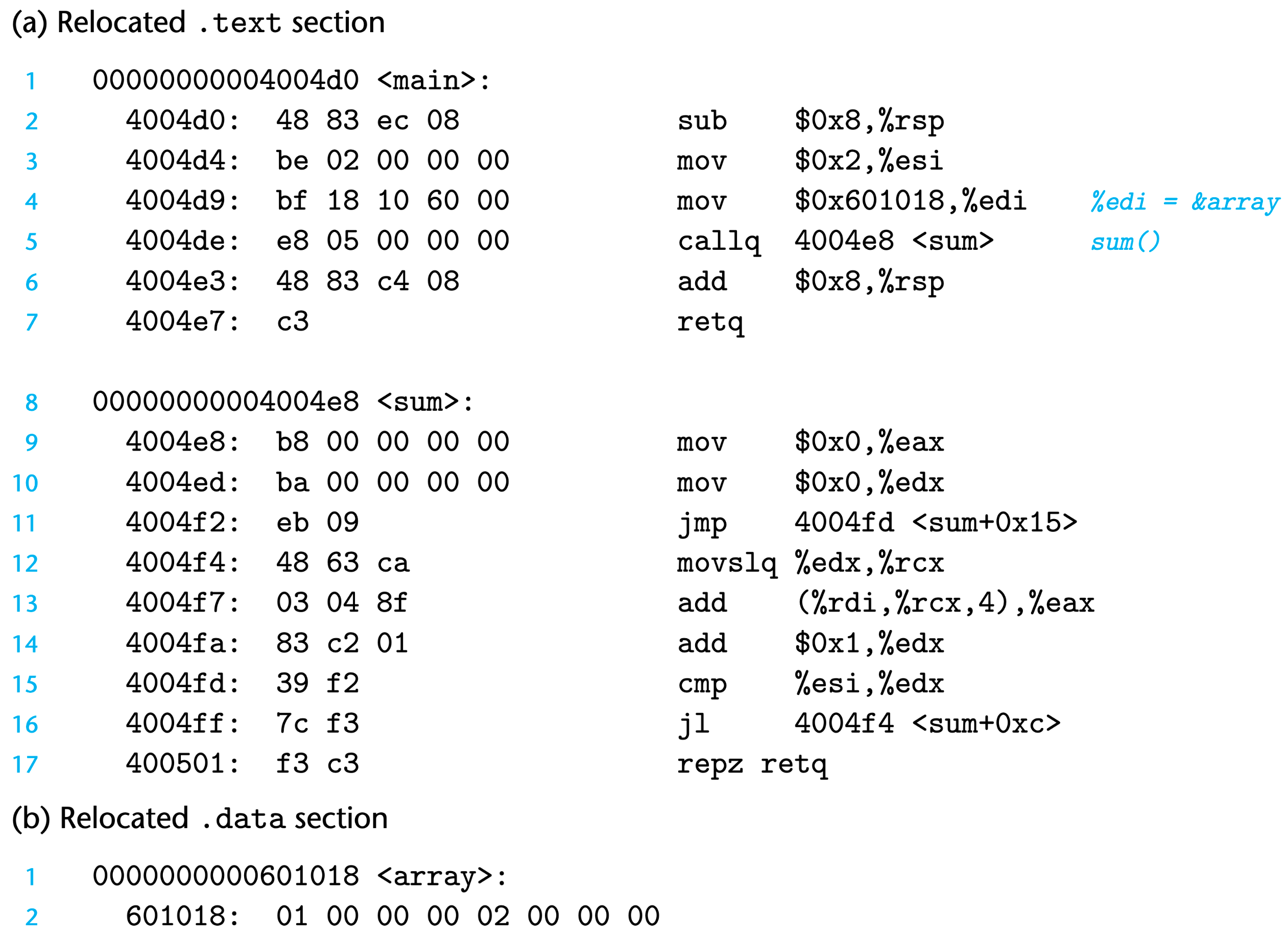
Here the main function referened 2 global symbols, array and sum. For each reference, the assembler generated a relocation entry, displayed on the following line[1]. The assembly code for main.c is as shown below:

Relocating PC-Relative References
In line 6 of the assembly code, main function calls function sum, defined in sum.o, and the actual call instruction has an offset of 0xe. The instruction consists of a 1-byte opcode 0xe8, and following 32-bit PC-relative reference to the target sum.
Note that when the programs is executing this call instriction, the PC counter is pointing at the actual run-time address of the call instruction + 5.
Thus the corresponding relocation entry r shall be:
1 | |
Now, suppose the linker has determined the address of the .text section of main.o as ADDR(S) = ADDR(.text) = 0x4004d0
The address of sum is assigned as ADDR(r.symbol) = ADDR(sum) = 0x4004e8
Using the algorithm described above, the address of the bias is
1 | |
And it’s to be modified to:
1 | |
Thus the call instruction is converted to

The run-time address for this instruction is naturally 0x4004de, and when executing this instruction, the cpu does 2 steps,
- Push pc to task
- PC <– PC +
0x5=0x4004e8
which hands over the control to function sum
Relocating Absolute References
Relocating for absolute references are quite straightforward. Consider line 6, the instruction mov has an offset of 0x9, consisting of 1-byte opcode, and a following 32-bit absolute reference to array. The corresponding relocation entry r shall be
1 | |
Supposes the linker has determined the
ADDR(r.symbol) = ADDR(array) = 0x601018
Then the linker updates the reference by
1 | |
Finally the instruction is converted to
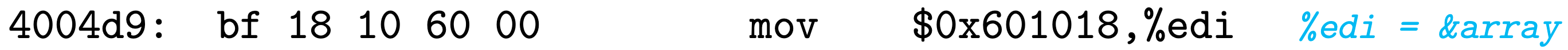
Putting all pieces together, we have the fully relocated .text and .data sections in the final executable object file. When we want to execute the output, the loader directly copy the bytes from these sections into memory without any further modification.
Executable Object Files
Here is the anatomy of a typical ELF executable file
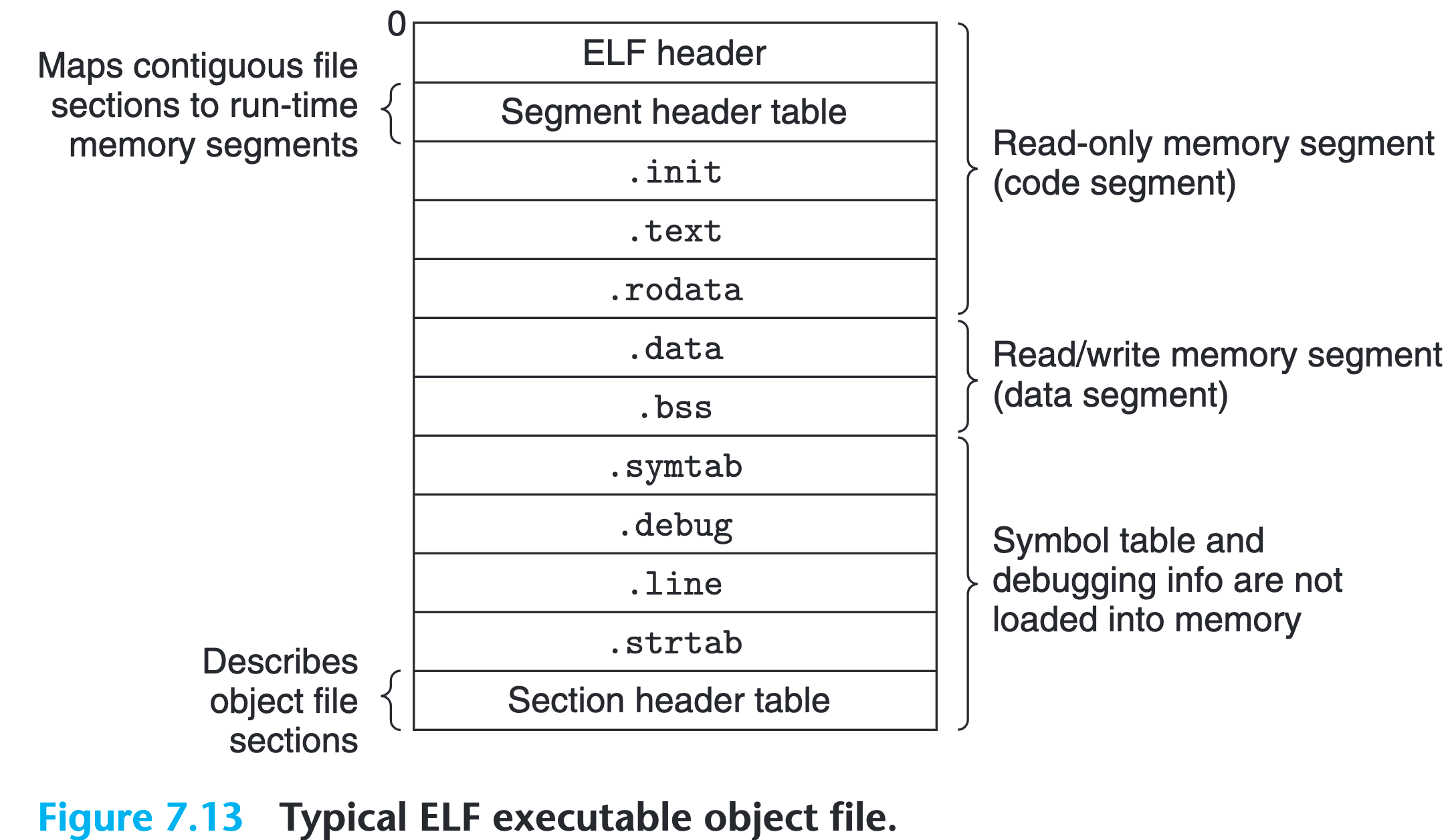
The format is similar to relocatable object file. ELF header describes the overall [format](#Elf format) of the file, plus the entry point, the address of the first instruction to execute.
The .init section defines a small function, called _init, that will be called by the programs initialization code.
Since the executable is fully linked, it doesn’t need any .rel section.
A more detailed description of ELF executable object file anatomy: ELF_Executable_and_Linkable_Format_diagram) (wikimedia.org)
ELF executable are designed to be easy to load into memory, and contiguous chuncks of the executable file are mapped to contiguous memory segments. This mapping relationship is described by the program header table[2]. The following picture shows part of the header table for prog

| Field | Describe |
|---|---|
| off | offset in the object file |
| vaddr | virtual memory address to begin |
| paddr | physical memory address to begin |
| align | alignment requirement |
| filesz | segment size in object file |
| memsz | segment size in memory |
| flags | run-time permission flags |
Line 1 and 2 generally states: the first segment (code segment) has read/execute permissions, starting at 0x400000, has 0x69c total size in memory, which is initialized with 0x69c bytes starting at offset 0x0 of the executable object file.
Line 3 and 4 generally states: the second segment (the data segment) has read/write permissions, starting at memory address 0x600df8, with a total memory size of 0x230 bytes, and is initialized with 0x228 bytes at the offset 0xdf8 of the executable object file. Remember the executable file won’t store anything concrete in .bss section, but for programs, those variables need actual space. Thus the remaining 0x8 bytes (0x230 - 0x228) are for those variables.
For any segment $s$, the linker must choose a starting address, vaddr, such that
$$
vaddr \mod {align} = off \mod{align}
$$
Here off is the offset of the segment’s first section in the object file, and align is the alignment specified earlier in the program header.
For data in the figure above, we have
$$
vaddr\mod{align}=\mathbf{0x600df8}\mod{\mathbf{0x200000}}=\mathbf{0xdf8}\
off\mod{align}=\mathbf{0xdf8}\mod{\mathbf{0x200000}}=\mathbf{0xdf8}
$$
Segments stored in the executable file doesn’t always equal with the size compared with the size after it’s loaded into memory. That’s why sometimes maybe the linker will need to discard some main memory space which is too small to fill a memory page.
Why do we need this alignment?
Because when running a program on modern operating systems, every segment of the executable file isn’t always completely loaded in main memory, due to virtual memory technology. By putting constraints on the alignment, the operating systems can transfer data in executable object files more effectively to main memory.
Loading Executable Object Files
When running an executable object file from shell, shell invokes loader, some of the memory-resident operating system code.
By the way, any linux program can invoke loader by calling execve function.
Then starts the process that the laoder copies the code and data in the executable object file from disk into memory and jumps to its first instruction, or entry point. The process is known as loading.
Every running Linux program has a similar run-time memory image as shown below
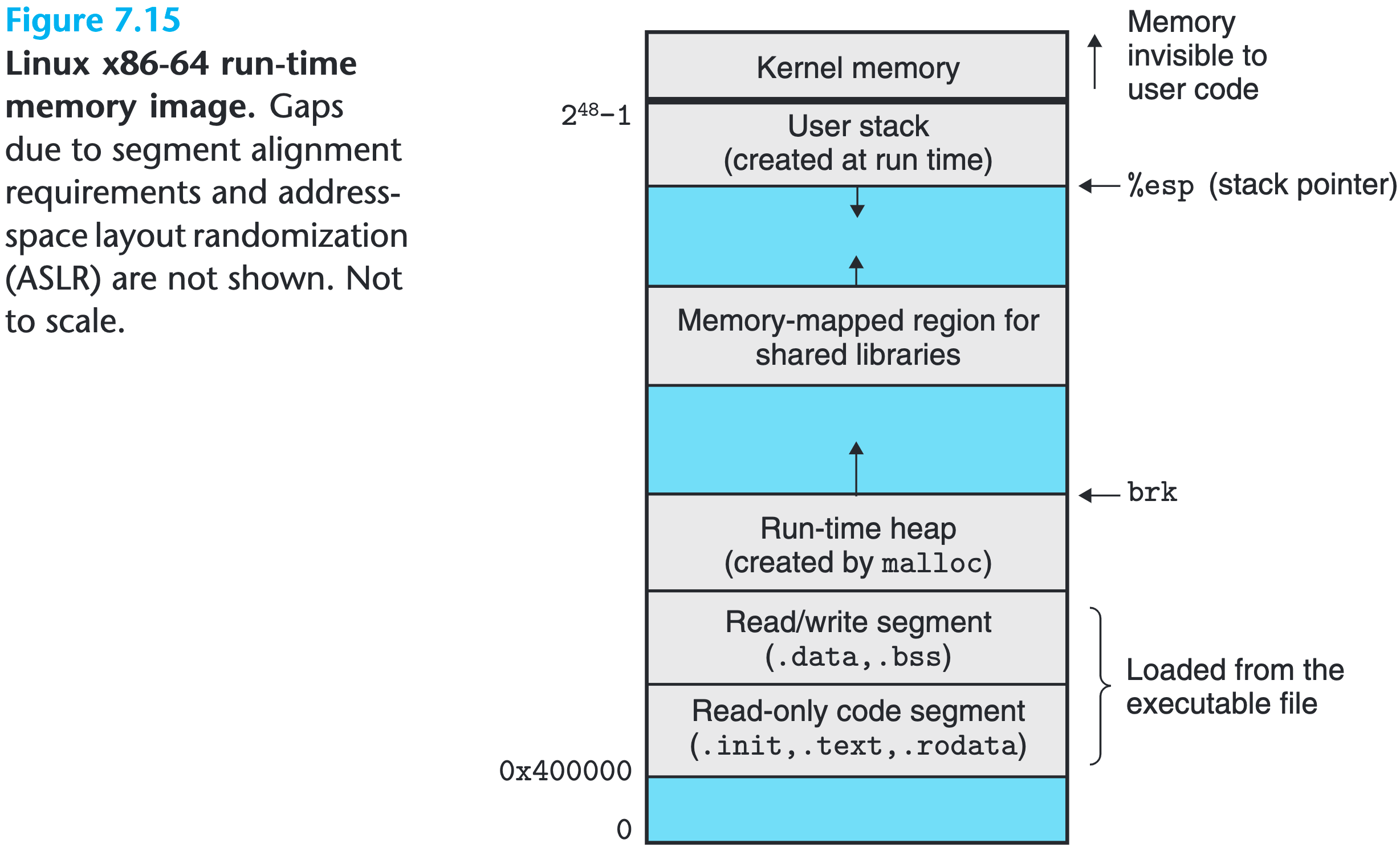
On Linux x86-64 systems, the code segment always starts at 0x400000, and the largest legal user stack address is $2^{48} - 1$, where user stacks begin and grows downward. Memory above $2^{48}$ are reserved for the code and data in the kernel, the memory-resident part of the operating system.
When the loader runs, it creates a memory image similar to the picture above, and then follow the guid in program header table, copying chuncks of data from the executable object file into the code and data segments.
Then the loader jumps to the program’s entry point, which is always the address of _start function. This function is defined in the system object file crt1.o and is the same for all C programs. The _start function calls the system startup function, __libc_start_main, which initializes the execution environment, calls the user-level main function and handles its return value, and finally returns control back to kernel, if necessary.
Dynamic Linking with Shared Libraries
So far we’ve discussed static libraries know understand how we can make use of static libraries to distribute large collections of functions to applications. However, there are still underlying drawbacks. For one thing, static libraries, just like other software, need maintaining and updating. If application programmers want to use the most recent version of a library, they must explicitly link their programs against the updated library file.
For another, it’s about saving memory space. Almost every C program uses standard I/O functions, like scanf and printf. As long as some running program has the standard I/O functions in their source code, the code for these functions will be incapsulated in their .text section of executable obejct file and then in their code segment of the memory image. For a system runing hundreds of processes, this could be a significant waste of resource.
How does the loader really work?
The previous discussion on loading has deliberately left out some concepts.
The complete view of how loading really works is:
Each program in Linux system runs in the context of a proess and has its own virtual address space. When the shell runs a program, it forks a child process.
The child process is primarily a duplicate of the parent process, and then it invokes the loader by a system call to execve.
The loader then deletes the child’s existing virtual memory segments and creates a new set of code, data, heap and stack segments, among which stack and heap segments are initialized to 0, the code and data segments are initialized to the contents of the executable file by mapping pages in the virtual address space to page-size chunks of the executable file.
Finally, the loader jumps to the address of _start, which eventually calls the user-level main function.
Aside from some header information, there is actually no copying of data from disk to memory during loeading. The real copying is defered until a page fault.
Shared libraries are modern innovations that is used to address the disadvantage of static libraries.
A shared library is an object module that, at either run time or load rime, can be loaded at an arbitrary memory address and linked with a program in memory. This process is called dynamic linking, and is performed by a program called dynamic linker . In Linux system, shared libraries are also called shared objects, with suffix .so, while on windows, they have suffix .dll.
There are 2 ways of sharing a shared object:
- In terms of file system and disk space, there is exactly one .so file for a articular library. Any program that referenced this library won’t need to copy its sub-object modules and embed it into the executable object file.
- In terms of main memory, a single copy of the shared object in main memory can be used by different running processes.
To build a shared library, invoke gcc with flag -shared.
The linking command is quite similar to that of linking static libraries.
Here the flag pic is to instruct the compiler to gernate position-independant code, which will be discussed later. The following picture illustrates how the procedure of loading a program when involving dynamic linking.
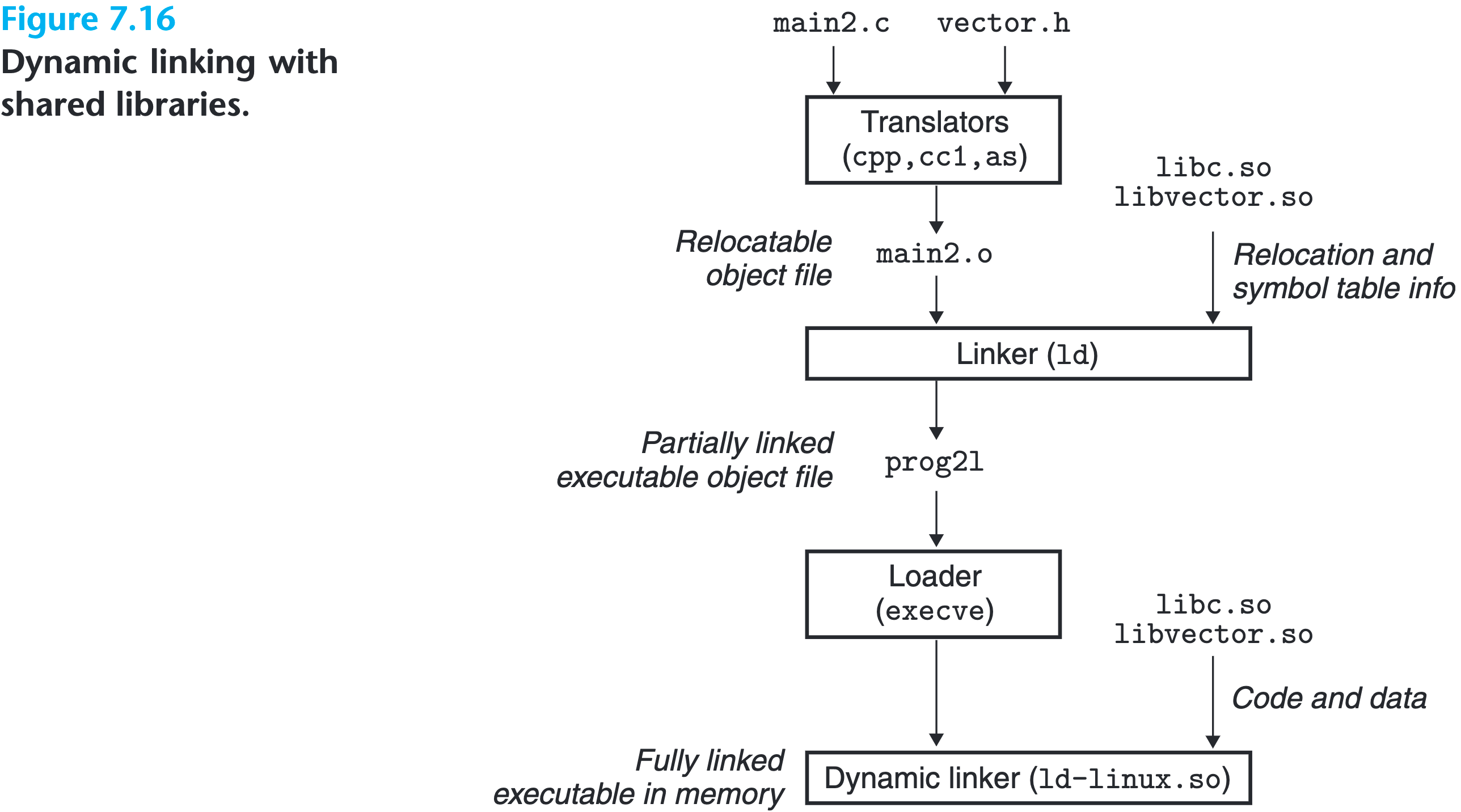
It’‘s important to realize that none of code or data sections from libvector.so are copied into the executable object file prog2l. Instead, the linker copies some. relocation and symbol table information that will allow references to code and data in libvector.so to be resolved at load time.
When the loader loads and runs prog2l as discussed in the [previous headline](#Loading Executable Object Files), it notices that there is a .interp section, which has the path name of the dynamic linker, which is itself a shared object( on Linux system, it is ld-linux.so). Instead of passing control to the application, the loader loads and runs the dynamic linker.
The dynamic linker finishes the remaining linking task by performing:
- Relocating the text and data of libc.so into some memory segment
- Relocating the text and data of libvector.so into another memory segment
- Relocating any references in prog2l to symbols defined by libc.so and libvector.so
Finally, the dynamic linker passes control to the application and from this point on, the locations of the shared libraries are fixed and no longer change during the executing of the program( Note: this is load time linking, the program is still fully linked before executing ).
Loading and Linking Shared Libraries from Applications
Till now, we only discussed running programs which are fully linked before really executing. The linking of the executable object file is either fully completed during compile and link time by using static libraries, or is partially completed and some of this process is postponed until load time, by invoking the dynamic linker to finish the rest.
Is it possible that the running executable can request the dynamic linker to load and link arbitrary shared libraries even if itself is not linked against the according shared librariy?
The answer is yes, and it has 2 significant examples:
Distributing software.
Developers of MSWindows apps frequently update software by updating its shared libraries.
Building high-performance web servers.
Functions for generating use-specific contents are placed in shared libraries. When a web request comes in, the server loads the library into memory and call functions in it.
Shared libraries and the Java Native Interface
When browsing JDK source code, we might find some methods marked as native and nowhere to look for its implementation. Acually, that’s called Java Native Interface( JNI ), which allows native C/C++ to be called from Java programs.
These native C/C++ functions are compiled into shared libraries. When a running Java program attempts to invoke some JNI functions, the Java interpreter uses something like
dlopeninterface to dynamically link and load those libraries and then call their functions.
Position-Independant Code(PIC)
We’ve discussed the 2 significant advantages that shared libraries have over static libraries, one of which being allowing multiple running processes to share a single copy of library code in memory.
Were us to implement this feature, any idea?
One approach would be to presume the existence of some libraries and assign a chunk of memory address to them, regardless of whether the library is actually used or not, and at the same time requires the loader to always place shared libraries there. This solution is straightforward, yet problematic. First, it occupies memory address even if it’s not referenced. Besides, we need a mechanism to maintain those chunks of memory. If the library is modified, we need to make sure it still fits in its chunk, or some chunks would overlap. If a new library is created, again we need to find its chunk somewhere. Once the number of libraries grow with each having different versions, the virtual address space would be full of small unused holes.
Modern systems compile code segments of shared modules while ensuring they can be loaded anywhere in memory, without having to be modified by the linker. This would enable unlimited number of processes to shared the same copy of the code segment of the library, while each process still gets its own read/write data segment of the library.
Those code that can be loaded needing no further relocations is known as position independent code(PIC)
To signal gcc, use -fpic. Shared libraries must be compiled with this flag.
On x86_64 systems, references to symbols in the same executable object module requires no special treatment to be PIC. Those references can be compiled using PC-relative addressing and relocated by the static linker. Only references to external procedures and global variables that are defined by shared modules need special techniques.
PIC data reference
Compilers generate PIC references for global variables base on an interesting fact:
Wherever an object module is loaded into the main memory( shared object module/ executable object module), once everything is relocated, the distance between the very instruction and the very data object that’s referenced by the instruction is a run-time constant, and the procedure of relocating won’t change the constant at all. Although the actual physical memory address, or the virtual memory address of the program might vary from time to time, the distance is always a run-time constant, always figured out upon the end of loading.
Compilers then generate PIC references to global variables by creating a table, global offset table( GOT ), at the beginning of the data segment.
The table is 8-byte per entry, and each entry corresponds to one global data object( data/ procedure) that’s referenced by this object module. Also, the compiler generates relocation record accordingly, for each member in the GOT. At load time, the dynamic linker relocates each GOT entry so that the entry has absolute address for each symbol.
If libvector.so is compiled using -fPIC, the process of referencing addcnt shall be reflected by the following picture
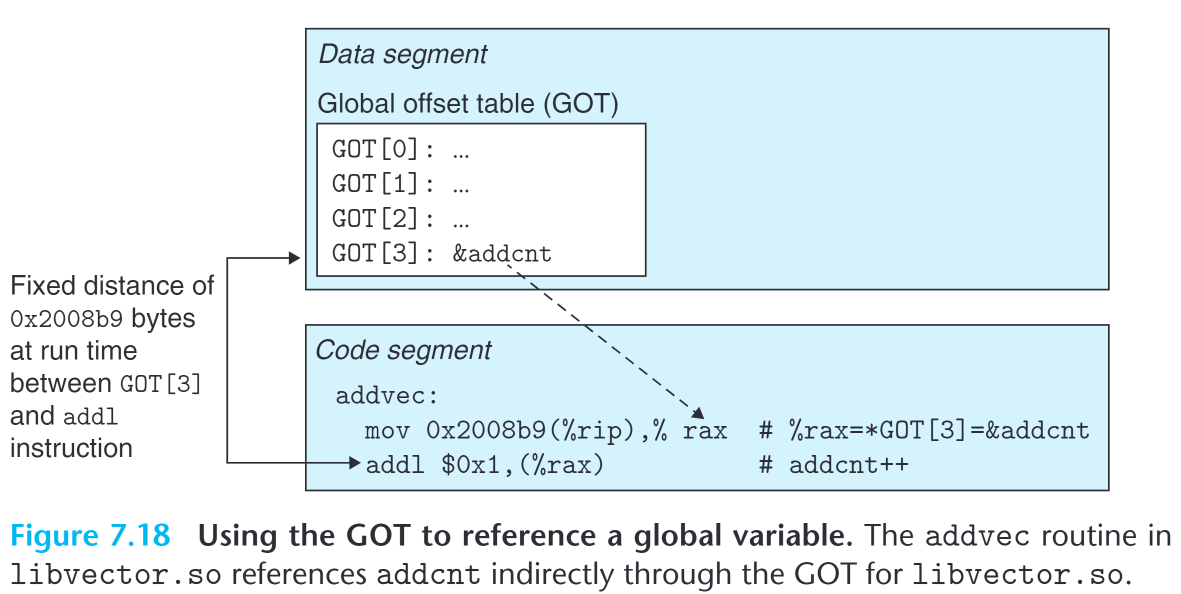
Note that the global variable addcnt is defined by libvector.so, so that technically, the compiler won’t need GOT to reference it. Were it defined by other modules, GOT must be exploited.
PIC function calls
To simplify the discussion below, we assume all shared libraries are self-contained( They don’t have any unresolved references).
When a program invokes functions from some shared library, the compiler has no way of predicting the run-tiem address of them. In fact, according to the discussion above, the compiler doesn’t even know whether a function is defined by its bunch of input source files or, its definition is provided by a library.
The normal solution would be generating relocation entries for those functions while having the executable object file only partly linked. When the program is about to be loaded into memory, the dynamic linker will see to resolving the rest of references. The dynamic linker will decide where to load the rest of shared objects.
This works, and pratically in most cases. But this approach is not PIC, because to relocate all the references, the dynamic linker definitely needs to modify the code segment. The GNU compilation system solves this problem using lazy binding, which defers the binding of each procedure address until its called for the first time. Typically, a program will only call a relatively small set of functions among thousands of those exported by a shared library. Consequently at load time, the dynamic linker can escape from relocating for the same function wherever its referenced. Naturally, it costs non-trivial runtime overhead for binding, but each call thereafter costs a single instruction and a memory reference for indirection.
Lazy binding is implemented by close cooperation between GOT and procedure linkage table (PLT). If an object module calls a function defined in shared libraries, then it has its own GOT and PLT. Recall that the linker knows whether a function is defiend by a shared library or not, and typically shared libraries has its own GOT but is used when relocating global data references in other object moduels. The GOT is in the data segment and the PLT is in the code segment.
The PLT is an array of 16-byte code entries. The following picture illustrates what happend when the program subsequently calls addvec

PLT[0] is a special entry that jumps into the dynamic linker. Each shared library function called by the executable has its own PLT entry, and theoretically each of such entry is responsible for invoking its corresponding function. PLT[1] (not painted) invokes the system startup function __libc_start_main, which initializes the execution environment and calls main function, and handles its return value. Entries starting at PLT[2] invoke functions called by the user code. In the picture, PLT[2] and PLT[3] invoke addvec and printf accordingly.
The GOT, as is introduced above, is an 8-byte entry table, each entry for the address of each global data object, at least this holds for shared objects. Here GOT stores something different as is used in conjunction with PLT.
GOT[0] and GOT[1] stores information that the dynamic linker needs when it resolves function addresses. GOT[2] is the entry point for the dynamic linker in ld-linux.so module. From here on, each of the remaining entries corresponds to a called function whose address need resolving at run-time. Each of those entries also has its matching PLT entry. e.g, GOT[4] -> PLT[2]. Initially, the GOT entry points to the second instruction in its corresponding PLT entry.
The first call to addvec triggers the following steps:
- Instead of directly calling addvec, the program calls into PLT[2], the PLT entry for addvec
- THe first PLT instruction indirectly jumps *GOT[4], at this time GOT[4] is pointing to the next instruction
0x4005x6, which is exactly the next instruction of this indirect jump in PLT[2] - An ID for addvec(0x1) is pushed onto the stack, then PLT[2] jumps to PLT[0]
- PLT[0] pushes an argument for the dynamic linker indirectly through GOT[1], then jumps into the dynamic linker through GOT[2]. Then the dynamic linker takes the 2 top arguments at the stack and determines the run-time location of
addvec, overwriting GOT[4] to this address, and passes control toaddvec.
From then on, any following calls to addvec:
Calls into PLT[2]
Jumps indirectly to
*GOT[4], which is exactly the address ofaddvec
Library Interpositioning
Imagine what we can build if we can intercept any calls to shared library functions and execute our own code. Linux linkers support this technology, called library interpositioning.
Using library interpositioning, you can trace the numebr of times a particular function is called, validate and trace its input and output values, or event replace it with a completely different implementation.
Typically, we will choose a target function to interpose on, and create a wrapper function whose signature is identical to the target function. Using some particular interpositioning mechanism, the system is tricked into calling our wrapper function. The wrapper function usually has its own logic, but will eventually calls the target function and return its result.
Interpositioning can occur at compile time, link time, or run time, distinguished from in which stage the function is acutally replaced.
Compile Time Interpositioning
This one is pretty simple, we define macros or using aliases to substitute calls to target functions quietly.
1 | |

Link Time Interpositioning
By using “-f –wrap” flag, we can implement link time interpositioning. This tells the linking to resolve references to symbol f as __wrap_f, and resolve references to symbol __real_f as f.
1 | |
Run Time Interpositioning
Recall how we implement compile time interpositioning and link time interpositioning. Compile time interpositioning requires we have access to source files of the program, and link time interpositioning requires access to relocatable object files. Here is aother mechanism to interpositioning at run-time, and as you might wish, only requires access to the executable object file.
Based on the dynamic linker’s LD_PRELOAD environment variable. Once it’s set to a list of shared library pathnames, when laoding this program, the dynamic linker LD-Linux.so will search LD_PRELOAD first, before any other shared libraries when encountering unresolved references.
Theoretically with this feature, we can interpose on any functions in any shared library, when executing any program[3].
1 | |


Appendix
C local static variables
static variables in functions are not managed on the stack. Its space is allocated by compiler in .data/ .bss for each definition, and each definition corresponds to a unique symbol in the symbol table.
1 | |
As for the program above, the compiler exports a pair of local linker symbols with different names to the assembler. e.g: x.1 for f::x, x.2 for g::x
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!